-
Choerodon平台版本:0.6.0
-
运行环境:公司提供
问题描述:搭建kubernetes集群时,如果集群是一台主节点和多台从节点,只有主节点上安装etcd服务,这样无法在猪齿云上激活。如果是所有主机都安装主节点、从节点和etcd等服务就可以激活,请问这是为什么?

Choerodon平台版本:0.6.0
运行环境:公司提供
问题描述:搭建kubernetes集群时,如果集群是一台主节点和多台从节点,只有主节点上安装etcd服务,这样无法在猪齿云上激活。如果是所有主机都安装主节点、从节点和etcd等服务就可以激活,请问这是为什么?
一个集群是可以安装多个环境客户端的。
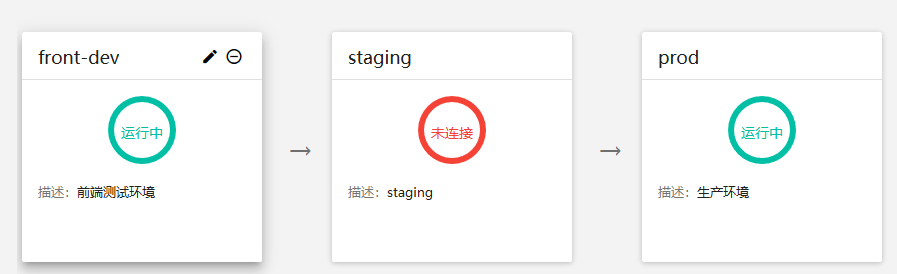
但是为什么我无法激活多个,执行后集群那些pod已经启动了,但是显示未连接,如上述的staging。
我在另一个集群中试了一下,可以正常激活,如上述的prod
同时还请帮忙解答下最上面的那个问题,是不是kubernetes集群只能使用那种不分主从的,就是一台主机上同时安装主从服务。
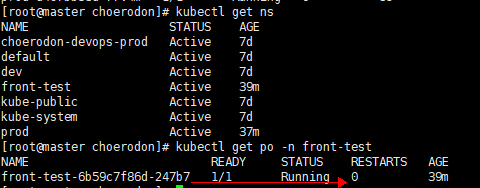
从你的截图中,我并没有看到你在这个集群执行安装staging 环境客户端的命令,namespace都没有创建,

staging只是一个名称,它的编码是front-test
执行命令为
if ! [ -x “$(command -v kubectl)” ]; then
echo ‘Error: kubectl is not installed.’ >&2
exit 1
fi
if ! [ -x “$(command -v helm)” ]; then
echo ‘Error: helm is not installed.’ >&2
exit 1
fi
kubectl create namespace prod
helm install --repo=http://chart.choerodon.com.cn/choerodon/framework/
–namespace=prod
–name=prod
–version=0.6.0
–set config.connect=ws://devops.service.choerodon.com.cn/agent/
–set config.token=72dcee37-34b5-4a78-8693-bc355fcacffb
–set config.envId=47
–set rbac.create=true
choerodon-agent
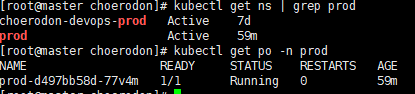
你贴一下这个这个prod 客户端的日志。
[root@master backend]# kubectl logs prod-d497bb58d-77v4m -n prod
I0620 14:34:44.170965 1 controller.go:81] Started “configmap”
I0620 14:34:44.171068 1 controller.go:81] Started “replicaset”
I0620 14:34:44.171129 1 controller.go:81] Started “pod”
I0620 14:34:44.171216 1 controller.go:81] Started “endpoint”
I0620 14:34:44.171237 1 controller.go:81] Started “service”
I0620 14:34:44.171261 1 controller.go:81] Started “secret”
I0620 14:34:44.171294 1 controller.go:81] Started “ingress”
I0620 14:34:44.171321 1 controller.go:81] Started “deployment”
I0620 14:34:44.171352 1 controller.go:81] Started “job”
I0620 14:34:44.171395 1 client.go:51] Started agent
I0620 14:34:44.171939 1 configmap_controller.go:68] Starting Pod controller
I0620 14:34:44.171949 1 configmap_controller.go:71] Waiting for informer caches to sync
I0620 14:34:44.171985 1 replicaset_controller.go:67] Starting Pod controller
I0620 14:34:44.171989 1 replicaset_controller.go:70] Waiting for informer caches to sync
I0620 14:34:44.172376 1 pod_controller.go:69] Starting Pod controller
I0620 14:34:44.172395 1 pod_controller.go:72] Waiting for informer caches to sync
I0620 14:34:44.172481 1 endpoints_controller.go:147] Starting endpoint controller
I0620 14:34:44.172499 1 controller_utils.go:1019] Waiting for caches to sync for endpoint controller
I0620 14:34:44.172545 1 service_controller.go:68] Starting Pod controller
I0620 14:34:44.172549 1 service_controller.go:71] Waiting for informer caches to sync
I0620 14:34:44.172595 1 secret_controller.go:68] Starting Pod controller
I0620 14:34:44.172599 1 secret_controller.go:71] Waiting for informer caches to sync
I0620 14:34:44.172621 1 ingress_controller.go:68] Starting Pod controller
I0620 14:34:44.172626 1 ingress_controller.go:71] Waiting for informer caches to sync
I0620 14:34:44.172657 1 deployment_controller.go:68] Starting Pod controller
I0620 14:34:44.172663 1 deployment_controller.go:71] Waiting for informer caches to sync
I0620 14:34:44.172713 1 job_controller.go:72] Starting Pod controller
I0620 14:34:44.172718 1 job_controller.go:75] Waiting for informer caches to sync
I0620 14:34:44.272208 1 configmap_controller.go:109] Started workers
I0620 14:34:44.272490 1 pod_controller.go:111] Started workers
I0620 14:34:44.272491 1 replicaset_controller.go:108] Started workers
I0620 14:34:44.272632 1 controller_utils.go:1026] Caches are synced for endpoint controller
I0620 14:34:44.272653 1 secret_controller.go:109] Started workers
I0620 14:34:44.272698 1 service_controller.go:109] Started workers
I0620 14:34:44.272766 1 job_controller.go:113] Started workers
I0620 14:34:44.272798 1 ingress_controller.go:109] Started workers
I0620 14:34:44.272831 1 deployment_controller.go:109] Started workers
E0620 14:35:24.178329 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:60148->10.233.0.10:53: i/o timeout
E0620 14:36:09.181156 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:47389->10.233.0.10:53: i/o timeout
E0620 14:36:54.182931 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:54618->10.233.0.10:53: i/o timeout
E0620 14:37:39.185208 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:37344->10.233.0.10:53: i/o timeout
E0620 14:38:24.187057 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:36292->10.233.0.10:53: i/o timeout
E0620 14:39:09.188671 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:40565->10.233.0.10:53: i/o timeout
E0620 14:39:54.190649 1 client.go:68] dial error ws://devops.service.choerodon.com.cn/agent/?version=0.6.0&envId=47&key=env:prod.envId:47: dial tcp: lookup devops.service.choerodon.com.cn on 10.233.0.10:53: read udp 10.233.66.117:35678->10.233.0.10:53: i/o timeout
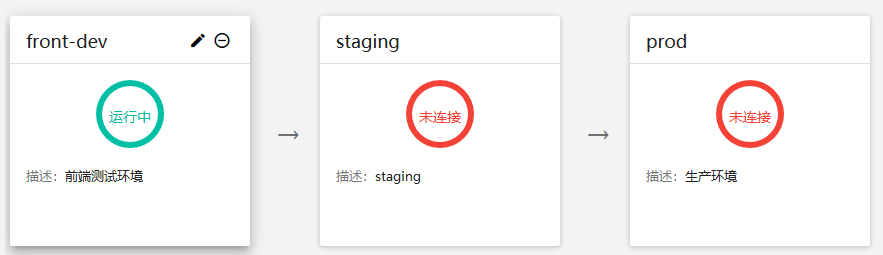
连接上的可以ping通,连接不上的是ping不通的。我发现如果这个pod在运行在一个节点上可以激活,在另一个节点上就无法激活。这是为什么呢?节点都是一样的,安装的主、从和etcd服务。
这应该是您的集群网络存在问题。所有节点是否都能访问外网或者是否有修改某个节点的iptables?
所有节点都可以访问外网,修改iptables是指什么?防火墙吗?我使用的是centos7。firewalld防火墙已经关闭。
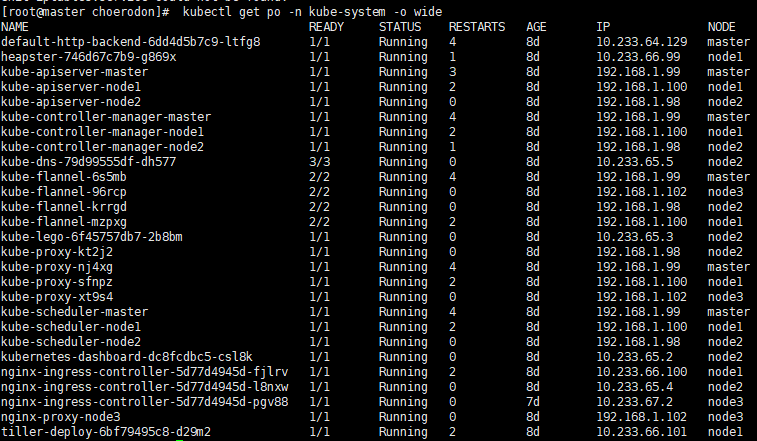
执行 kubectl get po -n kube-system -o wide 查看下各组件的状态。
使用下面命令尝试重启flannel网络再试一下是否能ping通。
kubectl delete $(kubectl get po -n kube-system -o name | grep flannel) -n kube-system
可以了,谢谢了。为什么flannel启动了还会出现这种问题?
flannel在某些机器上偶尔会出现问题,可能是网络,资源等造成的。