
-
Choerodon平台版本: 0.20
-
遇到问题的执行步骤:
第一步安装K8S集群时候出错 -
文档地址:
http://choerodon.io/zh/docs/installation-configuration/steps/kubernetes/ -
环境信息(如:节点信息):
3个节点。每台配置相同,4核32G内存,160G磁盘 -
报错日志:
ingress,dns始终报错。
E0309 02:46:11.149523 1 reflector.go:126] pkg/mod/k8s.io/client-go@v11.0.0+incompatible/tools/cache/reflector.go:94: Failed to list *v1.Endpoints: Get https://10.244.64.1:443/api/v1/endpoints?limit=500&resourceVersion=0: net/http: TLS handshake timeout
E0309 02:46:11.149523 1 reflector.go:126] pkg/mod/k8s.io/client-go@v11.0.0+incompatible/tools/cache/reflector.go:94: Failed to list *v1.Endpoints: Get https://10.244.64.1:443/api/v1/endpoints?limit=500&resourceVersion=0: net/http: TLS handshake timeout
E0309 02:46:11.149523 1 reflector.go:126] pkg/mod/k8s.io/client-go@v11.0.0+incompatible/tools/cache/reflector.go:94: Failed to list *v1.Endpoints: Get https://10.244.64.1:443/api/v1/endpoints?limit=500&resourceVersion=0: net/http: TLS handshake timeout
E0309 02:46:11.149523 1 reflector.go:126] pkg/mod/k8s.io/client-go@v11.0.0+incompatible/tools/cache/reflector.go:94: Failed to list *v1.Endpoints: Get https://10.244.64.1:443/api/v1/endpoints?limit=500&resourceVersion=0: net/http: TLS handshake timeout
I0309 02:46:11.408196 1 trace.go:82] Trace[1363523066]: “Reflector pkg/mod/k8s.io/client-go@v11.0.0+incompatible/tools/cache/reflector.go:94 ListAndWatch” (started: 2020-03-09 02:46:01.407168536 +0000 UTC m=+2717.775732341) (total time: 10.00098729s):
Trace[1363523066]: [10.00098729s] [10.00098729s] END
apiserver的日志:
I0309 10:27:36.331434 1 controller.go:127] OpenAPI AggregationController: action for item v1beta1.metrics.k8s.io: Rate Limited Requeue.
I0309 10:27:38.538395 1 log.go:172] http: TLS handshake error from 10.244.0.2:55576: EOF
I0309 10:27:42.986372 1 log.go:172] http: TLS handshake error from 10.244.0.3:33126: EOF
I0309 10:27:53.833629 1 log.go:172] http: TLS handshake error from 10.244.0.3:33192: EOF
I0309 10:27:53.994790 1 log.go:172] http: TLS handshake error from 10.244.0.3:33198: EOF
I0309 10:28:05.015082 1 log.go:172] http: TLS handshake error from 10.2.7.193:61223: EOF
I0309 10:28:05.015160 1 log.go:172] http: TLS handshake error from 10.2.7.193:5259: EOF
I0309 10:28:15.754235 1 log.go:172] http: TLS handshake error from 10.244.0.3:33322: EOF
I0309 10:28:15.895375 1 log.go:172] http: TLS handshake error from 10.2.7.193:37036: EOF
I0309 10:28:15.994298 1 log.go:172] http: TLS handshake error from 10.244.0.3:33326: EOF
I0309 10:28:16.023085 1 log.go:172] http: TLS handshake error from 10.2.7.193:10716: EOF
I0309 10:28:16.023132 1 log.go:172] http: TLS handshake error from 10.2.7.193:13106: EOF
I0309 10:28:26.903397 1 log.go:172] http: TLS handshake error from 10.2.7.193:3461: EOF
I0309 10:28:26.986478 1 log.go:172] http: TLS handshake error from 10.244.0.3:33384: EOF
I0309 10:28:27.031064 1 log.go:172] http: TLS handshake error from 10.2.7.193:35425: EOF
I0309 10:28:27.033494 1 log.go:172] http: TLS handshake error from 10.2.7.193:59248: EOF -
原因分析:
看描述像是证书验证错误。安装过程中分发看起来都正常。
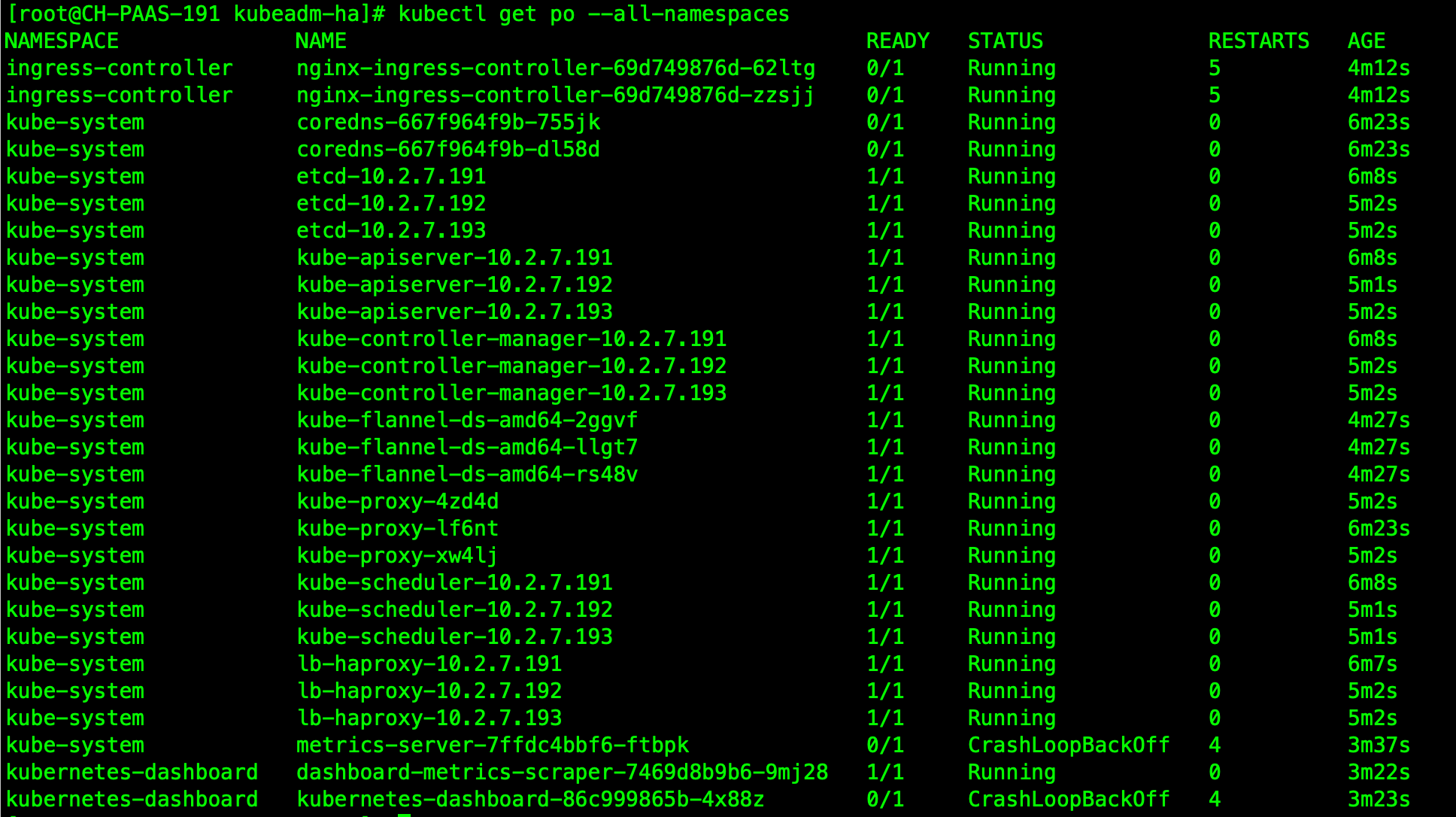
请帮忙分析一下,谢谢
