
1:因更换服务器,需迁移部署在原主机的nfs到新服务器,直接把nfs备份拷贝过去后,pod都报错了,见图一。
2:因更换服务器,需迁移部署在原主机的etcd节点到新的服务器,按照文档脚本执行增加etcd节点时报错,见图二。
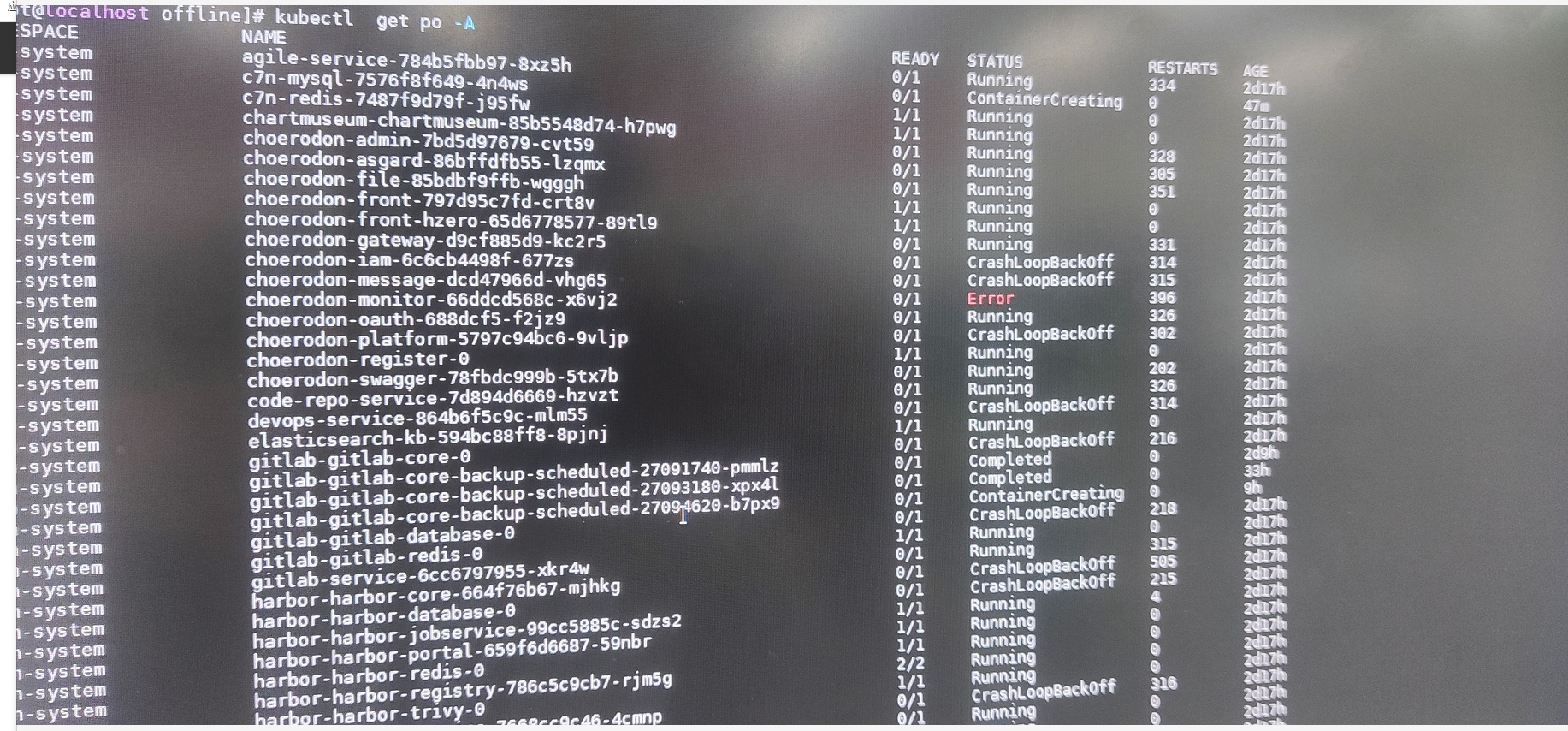

切换 nfs 服务器之后 ip 不变,直接将旧 nfs 服务器上的挂载目录复制到新服务器相同的挂载目录。
切换 nfs 服务器之后 IP 变化,主要根据猪齿鱼备份恢复操作
- 备份猪齿鱼的数据和配置,包括 mysql 和其他组件。
- 停用 c7n-system 下的所有pod,并删掉所有 pvc -—— 删掉 pvc,在 nfs 中并不会删掉挂载的对应文档,而是重命名为 archived-xx
- 使用新的 nfs 服务器创建一个 storageClass
- 修改 chartmuseum,mysql,redis,gitlab,harbor,neuxs,sonarqube 的 stoargeClass 为上一步创建,并使用 helm upgrade 更新配置
- 按照猪齿鱼恢复文档,恢复所有数据
- 最后按照顺序启动 choerodon-xx,devops-service 等pod
我一开始的时候把原nfs做了重命名,之后又改回去了,现在pod很多都是crashloopbackoff。这个得恢复成running在做备份吧。