
-
Choerodon平台版本: 0.2.0
-
遇到问题的执行步骤: 之前正常运行,不知什么原因挂了,然后重启一直失败
-
文档地址:
-
环境信息(如:节点信息):
-
报错日志:
-
原因分析:
-
疑问:
日志也看不出来啥请问如何排查问题

1.查看 Pod 状态: 使用以下命令查看 Pod 的状态,确保它们正在运行,并检查它们的事件,特别是任何错误或异常消息。
kubectl get pods -n c7n-system
kubectl describe pods -n c7n-system
kubectl logs -n c7n-system
2.查看容器状态: 如果 Pod 包含多个容器,请检查每个容器的状态和日志。
kubectl get pods -n c7n-system -o jsonpath=’{.spec.containers[*].name}’
kubectl logs -c -n c7n-system
3.检查网络问题: 确保 Pod 内容器能够正常访问所需的服务和资源。你可以使用 kubectl exec 进入 Pod,然后尝试与其他服务建立连接,例如数据库或 GitLab 服务。
4.检查资源使用情况: 使用以下命令查看 Pod 的资源使用情况,确保没有资源限制导致 Pod 无法正常运行。
5.查看 Pod 的 Readiness 和 Liveness Probe: 检查 Pod 配置中的 Readiness 和 Liveness Probe。这些探测可以帮助确定 Pod 是否已准备好接收流量以及是否健康。
6.查看事件: 使用以下命令查看与 Pod 相关的事件,以获取更多的上下文信息。
kubectl get events -n c7n-system
7.检查集群状态: 确保整个 Kubernetes 集群的状态正常。检查 Master 和 Worker 节点的日志以获取更多信息。
kubectl cluster-info
kubectl get nodes
8.查看 GitLab Runner 配置: 确保 GitLab Runner 配置正确,并且可以与 GitLab 服务建立连接。检查 GitLab Runner 的日志以获取详细信息。
9.尝试重新启动 Pod: 如果有必要,可以尝试删除并重新启动相关的 Pod。
kubectl delete pod -n c7n-system
经过筛选 以下服务存在问题
c7n-system gitlab-gitlab-core-0 0/1 CrashLoopBackOff 6 20m
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-65gvb 0/1 Error 0 10h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-88f87 0/1 Error 0 10h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-8n76z 0/1 Error 0 10h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-ldlnn 0/1 Error 0 10h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-vh9fx 0/1 Error 0 9h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-wb5dx 0/1 Error 0 10h
c7n-system gitlab-gitlab-core-backup-scheduled-28422300-zzpr2 0/1 Error 0 10h
c7n-system gitlab-gitlab-database-0 0/1 CrashLoopBackOff 15 56m
c7n-system gitlab-gitlab-redis-0 1/1 Running 0 20h
c7n-system gitlab-runner-gitlab-runner-6df6777d7b-jpbtl 0/1 Running 3 12m
c7n-system gitlab-service-fb4b4b985-mtdcc 0/1 Running 0 20h
按思路来首先解决gitlab-gitlab-database-0数据库服务启动失败
查看数据库服务日志
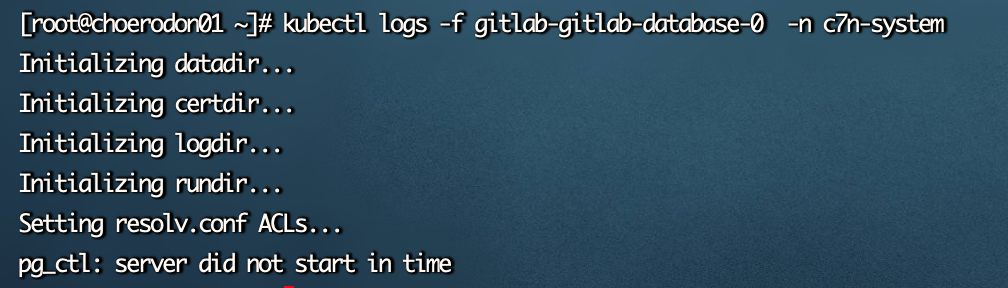
kubectl logs gitlab-gitlab-database-0 -n c7n-system
从提供的信息来看,数据库 Pod 的容器日志似乎没有提供有关详细问题的信息。现在需要更深入地检查问题。
尝试执行以下步骤:
查看数据库 Pod 的事件:
kubectl describe pod gitlab-gitlab-database-0 -n c7n-system
从提供的描述中,数据库 Pod gitlab-gitlab-database-0 处于不健康状态,可能的原因包括 Liveness 和 Readiness 探测的失败。
查看数据库 Pod 的详细日志:
kubectl logs gitlab-gitlab-database-0 -n c7n-system --previous
从日志来看,数据库 Pod gitlab-gitlab-database-0 的日志信息不足以提供详细的故障诊断。在 Initializing datadir… 阶段没有显示任何错误信息。
根据提供的信息,数据库 Pod (gitlab-gitlab-database-0) 处于 CrashLoopBackOff 状态。以下是一些可能的原因和进一步的调查步骤:
存储问题: 检查数据库 Pod 的持久卷声明(PersistentVolumeClaim)是否正常。有时,存储问题可能导致 Pod 启动失败。查看 PV 和 PVC 的状态。
kubectl get pv,pvc -n c7n-system
存储没问题排除
检查 PostgreSQL 错误日志: 进入 Pod 并查看 PostgreSQL 的错误日志,以获取更多有关启动失败的信息。
kubectl exec -it gitlab-gitlab-database-0 -n c7n-system – /bin/bash
cat /var/log/postgresql/postgresql-12-main.log
没有日志
需要进一步检查数据库本身的状态。在 gitlab-gitlab-database-0 容器内,尝试运行以下命令来连接 PostgreSQL 数据库并获取有关其状态的信息:
psql -h localhost -U postgres
根据连接错误,看起来 PostgreSQL 服务器没有在 localhost 上运行或者无法通过网络进行连接。
我们可以检查 PostgreSQL 服务器的运行状态。在 gitlab-gitlab-database-0 容器内,执行以下命令:
pg_isready -h localhost -U postgres
这个命令应该返回 "localhost:5432 - accepting connections”
由于 pg_isready 未能获得响应,这表明 PostgreSQL 服务器在 localhost 的 5432 端口上没有正在运行,或者有网络连接问题
我们可以检查 PostgreSQL 服务器是否已成功启动。在 gitlab-gitlab-database-0 容器内,运行以下命令:
ps aux | grep postgres
看起来 PostgreSQL 服务已经启动了,但是由于某些原因在启动时遇到了问题。关键是我们看到 postgres: startup 进程处于 D(不可中断)状态,这可能是由于启动过程中遇到的问题导致的。
尝试手动启动 PostgreSQL 并查看控制台输出,以获取更多的错误信息。
进入 PostgreSQL 数据目录
cd /var/lib/postgresql/12/main/
手动启动 PostgreSQL 服务:
sudo -u postgres /usr/lib/postgresql/12/bin/pg_ctl -D /var/lib/postgresql/12/main -l logfile start
并查看控制台输出:
cat logfile
在日志中,我们看到以下关键信息:
2024-01-17 00:30:18.710 UTC [48] FATAL: the database system is starting up